





К чему вообще все это?
Мониторинг 1С при помощи Prometheus+Grafana
Залогом стабильной работы объекта управления является отрицательная обратная связь, глубина которой обуславливает коэффициент устойчивости системы….. Боже мой. Как сладко спалось на лекциях по теории автоматического управления.
Тем не менее, информационная система на базе 1С вместе с пользователями – тоже можно рассматривать как некий объект управления, и для которого тоже была бы неплоха обратная связь.
В целом, мало какая ИС создана с умом изначально. С трудом можно представить себе консилиум специалистов, выдающих ТЗ на проектирование информационной системы на базе 1С, где были бы предусмотрены вот все эти рабочие и запасные сервера, рассчитан потребный объем ресурсов, учтены требования каналам связи и настройкам серверов. Еще труднее представить ситуацию, когда подобное ТЗ было бы досконально выполнено. Ибо это дорого.
Куда более обыденной является ситуация, в которой учетная система после первоначальной установки, развивается постепенно, силами постоянно сменяющих друг друга администраторов и приглашенных специалистов по 1С. Админы, как обычно, ничего знать про 1С не хотят, на каждого из спецов по 1С имеется по два мнения о прекрасном, а в итоге, система создается по бессмертным правилам «А что, если», «Тяп-ляп и в продакшн» и главным - «Работает – не трогай».
Результатом подобного подхода является обычно странный монстр доктора Франкенштейна, в котором каждый элемент создан отдельно, живет своей сложной жизнью, а вся система целиком ворочается, нервно, но вяло, лишь иногда реагируя на деятельность отдела эксплуатации.
Больше всего такая система напоминает корову на лугу, что бьет себя хвостом в ответ на нападения диких насекомых, в стиле тут укусили – там почесался.
Радости во всю эту картину добавляет простота изменения конфигурации 1С. И если в плане аппаратного обеспечения хоть и можно, но трудно наделать глупостей, то внутри конфигураций могут быть реализованы весьма причудливые и странные идеи.
При эксплуатации подобной системы, постепенно начинаешь хотеть странного. Было бы полезно понимать, что происходит в системе, как реагировать и куда бежать, когда в расчетной группе должен СЕГОДНЯ произойти расчет зарплаты, в учетном отделе-расчет себестоимости, а пользователи пишут письма и даже звонят с претензиями – «У меня не работает 1С».
На самом деле от такой диагностики мало толку и начинается нервная беготня, чтение священных книг, и прочие лихорадочные мероприятия. И слава электронной силе, что у нас регламентированный, а не оперативный учет ведь под погрузкой не стоит бетономешалка, в которой тебя и утопят.
Обычно это понимание «куда бежать» таится в голове главного 1С-ника,
Но вот такого 1С-ника нет, либо у него нет этого понимания, дело печально.
Итак, рассмотрим Информационную систему 1С, которая может быть представлена подобной схемой.
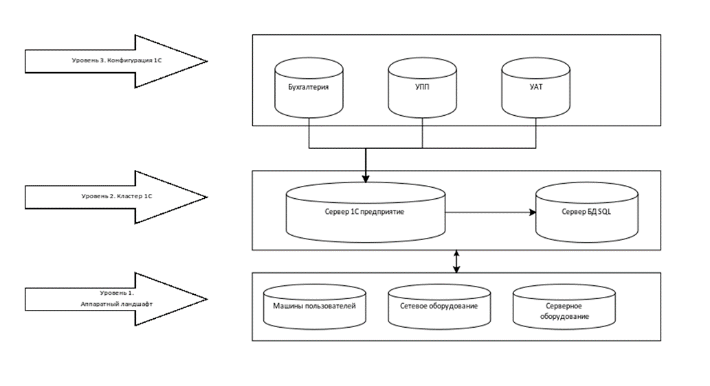
Базы 1С используют мощности сервера 1С Предприятия, который обращается к серверу БД, а все вместе они используют предоставленный им аппаратный ландшафт.
Казалось бы, что может пойти не так?
А может пойти ВСЁ.
И любое «не так» заканчивается сакраментальным – «1С не работает».
И без пресловутой обратной связи, вот так вот разобраться, что пошло не так – затруднительно.
Логичным представляется внедрение системы мониторинга, которая бы собрала сама данные и показала где и что пошло не так, а еще лучше предупредила о наступающем событии, ведь главный показатель работы отдела эксплуатации – тишина в кабинете.
И постепенно, проникая в мозг через ушибленный о клавиатуру лоб, в отделе эксплуатации возникает идея – нам нужен мониторинг состояния ИС.
Выбор системы мониторинга – сложный и запутанный процесс. Тысячи статей написаны по вопросам мониторинга. Ведутся священные войны. Секта свидетелей Zabbixa, вооружившись бубнами и заячьими лапками, агитирует неофитов. Всё так. Мы выбрали во всем многообразии связку Prometheus-Grafana. Почему?
Просто, бесплатно, логично, красиво, универсально.
Если по-простому, мы обвешиваем нашего Франкенштейна датчиками (они называется exporters). Датчики по запросу отдают набор данных, который называется метрикой. Ну да, термометр отдает значение метрики «температура» на правой ноге и левой руке.
С этих датчиков добрый Prometheus в белом халате, собирает данные, хранит у себя в собственной базе данных с меткой времени. Отдает показания в Grafana для отображения красивых картинок.
Grafana рисует нам картинки по тем данным, что Prometheus собрал и хранит.
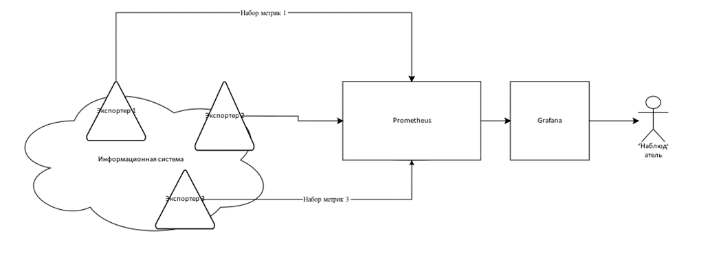
Если мы хотим снимать показания из системы мы должны:
Понять для себя какие показания мы хотим вообще собирать.
Внедрить в систему датчики, экспортеры.
Настроить их опрос Prometheus-ом.
Поручить Grafana строить красивые картинки.
Сидеть и умиляться примерно вот такому зрелищу:
Как уже говорилось, причин «Не работает 1С», может быть чрезвычайно много. Логичным видится идти от простого к сложному.
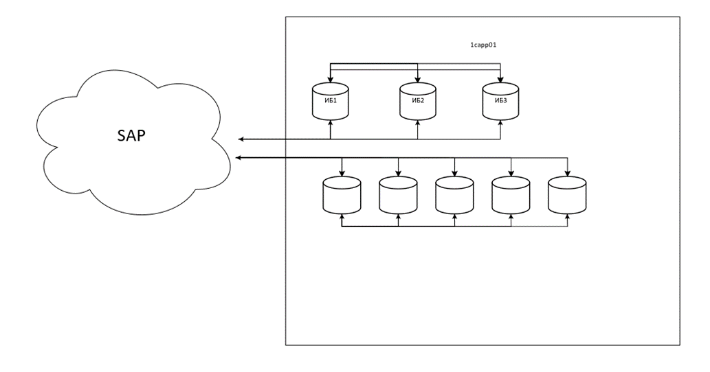
Для конкретности рассмотрим схему ИС, что стихийно сложилась за 10 лет эксплуатации системы 1С в одной из компаний:
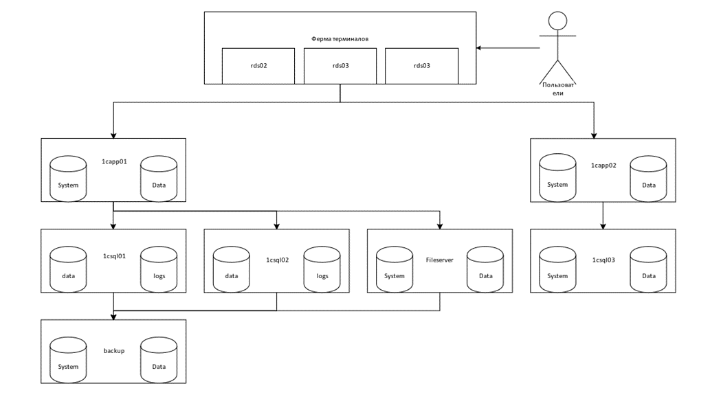
В этой системе
На уровне 1 пребывают виртуальные машины фермы терминалов rds02,03,04, виртуальные машины – серверы 1С предприятие 1capp01, 1capp02, виртуальные машины серверы MS SQL 1csql01, 02, 03, виртуальная машина - файл-сервер, физический бэкап сервер.
На уровне 2 находятся 2 сервера 1С Предприятие, 3 сервера MS SQL.
На уровне 3 функционируют 36 одновременно активных информационных баз 1С Предприятие разных конфигураций.
Уровень 1. Аппаратный ландшафт.
Аппаратный ландшафт – фундамент информационной системы. Если сбоит аппаратура – бесполезно забираться куда-то дальше.
Не надо быть знатоком священных книг, чтоб понять, что на системных дисках должно быть свободное место, что должно хватать оперативной памяти, очереди к дисковым подсистемам не должны быть постоянными. Нарушение любого из простых и очевидных правил ведет к сбоям в работе системы.
Итак, например, мы хотим собирать информацию о дисковых подсистемах, не на уровне даже выявления проблем производительности, но просто хотим, чтоб хоть как-то работало.
Для того, чтоб выяснить для себя эти вопросы, мы делаем что?
Ставим и запускаем как сервис экспортер Prometheus GitHub - prometheus-community/windows_exporter: Prometheus exporter for Windows machines на 1capp01, 1capp02, 1csql01-03, Rds02-04.
Ставим Prometheus. Download | Prometheus. Вообще для наблюдения конечно, следует выделить отдельную машину - сервер мониторинга. Это правильно, надежно, устойчиво. Однако, скрепя сердце, подойдет любая машина, в том числе и машина сисадмина.
Ставим упомянутом сервере мониторинга - Grafana Grafana: The open observability platform | Grafana Labs
Недолго настраиваем.
Радуемся.
Теперь внезапное разрастание c:\temp на сервере или каталоге сеансовых данных, переполнение журнала логов SQL, и прочее - не застанет нас врасплох.
Можем включить проверку скорости сетевого соединения, пресловутый ping, всё что хотим.
По результатам этого этапа внедрены: периодическая чистка каталога временных файлов, донастроен план обслуживания MS SQL, устранены проблемы с созданием бэкапов на сетевых дисках.
Уровень 2. Кластер 1С.
А что происходит внутри самого сервера 1С Предприятие? А что там на SQL-Сервере? На самом деле путь один
Ставим нужный экспортер GitHub - LazarenkoA/prometheus_1C_exporter: Мониторинг кластера 1С, отправка данных в prometheus
Подключаем опрос Prometheus
Видим количество занятых лицензий, объем памяти рабочих процессов и все то, что умеет стандартная утилита 1C rac, но с раскладкой во времени и с графиками:

По результатам внедрения на этом этапе устранены ошибки освобождения клиентских лицензий, настроен своевременный перезапуск рабочих процессов.
Уровень 3. Информационные базы.
А что происходит внутри самих информационных баз?
В системе 1С Предприятие функционируют одновременно 36 информационных баз 1С Предприятие, связанных между собой бесконечными обменами, и это только регламентный учет. А есть и оперативный учет, ведущийся в системе SAP/R3
Обмены конечно, запускаются и вручную, но в основном-регламентными заданиями, ночью. Пока все спят, жизнь сервера 1с Предприятия бывает еще и поинтенсивнее дневной.
И конечно, система, работающая на полном автомате, тем более нуждается в контроле. А если ночью не было связи с SAP? А если отключили свет? А все регламенты прошли и во всех-ли базах? И без ошибок-ли?
На самом деле, вот все что было выше – оно касается отдела эксплуатации.
А данные, что мы рассматриваем на этом уровне, касаются уже непосредственно хозяйственной деятельности.
Наш ответ прост, ну вы знаете
Ставим экспортер.
Настраиваем опрос.
Здесь нужны пояснения.
Для решения задач мониторинга процессов внутри информационных баз, был разработан специальный экспортер, в виде расширения 1С, способный устанавливаться на любую базу 1С Предприятие и превращать ее в источник данных для Prometheus. Разумеется, база должна быть опубликована на веб-сервере.
За основу взята разработка на GitHub - freewms/PDE: Встраиваемая конфигурация на платформе "1С:Предприятие" для сбора и передачи метрик в систему мониторинга Prometheus
Внесены исправления:
Работа в качестве расширения с минимально требуемым режимом совместимости.
Добавлено кэширование результатов вычисления метрик, для устранения риска перегрузки при слишком частом опросе Prometheus
Списки метрик, имена метрик, алгоритмы вычисления метрик для передачи определяются пользователем, имеющим соответствующие права, в пользовательском режиме.
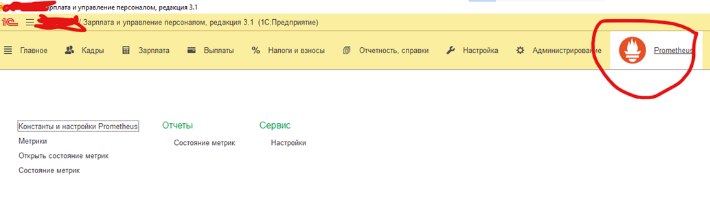
Расширение публикует результаты вычислений, Prometheus забирает их, Grafana отражает на экране
Например на скриншоте представлен алгоритм вычисления метрики – количество ошибок журнала регистрации с начала суток

Таким образом, мы легко отвечаем на вопрос, были-ли ночью ошибки и перезапуски регламентных заданий? Были записи об ошибках в журнале регистрации? Сколько и каких документов загружено из SAP? Прошла-ли загрузка выписок из клиент-банка? Во сколько были запущены клиентские сеансы и нет ли опоздавших на работу?
И прочие вопросы, уже касающиеся пользовательского уровня функционирования ИБ.
Благодаря этому расширению мы можем добавить в мониторинг любую информацию из информационной базы, которую можем получить средствами встроенного языка, имеющую числовое представление.
Заключение.
Вопрос мониторинга функционирования систем непрост. Все рассмотренные вопросы касаются стабилизации функционирования информационной системы, исключения ошибок автоматических процессов, минимизации рутинного ручного труда.
Некоторую информацию собранные данные могут дать и для оптимизации работы информационной системы. Многие параметры функционирования, описанные в наставлениях по оптимизации информационных систем, можно собирать быстрее, проще и нагляднее, чем посредством использования счетчиков Windows.
Система мониторинга не заменит анализа технологического журнала, однако большинство проблем повседневной эксплуатации такого анализа и не требуют.
В общем, призываю использовать наработанный опыт.













